一次 vibe-coding 的不完全体验
前言
这篇文章不是教程,也不是那种“我说一句话,AI 就把项目写完了”的展示文。
我更想把它写成一次真实学习 AI 开发的复盘。虽然我接触 AI 已经很久了,从 ChatGPT App、豆包、千问,到 TUI 编程工具 opencode / codex / claude code,再到 ollama / omlx / lm studio / comfyui 这类本地运行方案,都陆续用过,但大多数时候还是停留在“一问一答”或者 IDE 自动补全这种比较轻量的用法上。我其实从来没有真正把它们当作一套完整的 AI 工程流程,正式放进自己的编码工作里。
这篇文章写的,就是我怎么从一个已经用了很久(原谅我懒,用得久但产出并不高)、却总觉得别扭的博客 Gmeek 工作流出发,试着改善写博客的流程,并把一个模糊想法一步步落成结果的过程:先用 ima 做调研,再把调研结果交给 superpowers 里的 brainstorming 去收敛方案,最后用 opencode 一点点把它落成一个能工作的 CLI:igmeek。
如果一定要给这次过程下个结论,那大概是:vibe coding 确实能加速,但它加速的从来不是“替你思考”,而是把你原本要反复整理、来回表达、不断校准的那些东西,压缩到了一个更密的节奏里。真正费时间的部分,还是需求边界、工程细节、测试反馈,还有那些看起来不大、但不修就根本不好用的问题。
不是从写代码开始,而是先确认问题是什么
这个项目的起点其实很朴素。我一直在用 Gmeek 写博客,它的思路很干脆:文章就是 GitHub Issue,打上 Label 才会被识别和发布。这个设计很巧,也很省事,尤其适合“全部放在 GitHub 上”的那套使用方式。我很喜欢作者的一篇文章 《人会死,但我的博客在GitHub中会万岁》,有兴趣的可以去读一下。
但真到高频写作的时候,问题就会一点点冒出来。你得在网页里写文章,改标签还得回到网页里点来点去;本地草稿这件事并不自然,写完了还得复制粘贴到 GitHub 网页上;图片和其他资源管理更谈不上舒服。它不是不能用,而是你每次写东西的时候,都会觉得自己的手被网页束缚了。
所以就有了一个“本地编辑,再推送”的想法。说实话,这个想法我已经有很久了,但一直没有付诸实践。回头看,这个仓库早在 25 年 7 月就创建了,拖了半年多,才算真正开始。
在短视频和各种 vibe coding 教程的冲击下,我也确实学到不少东西。最开始我没有急着让 AI 写代码,而是先用 ima 的任务模式做了一轮调研,产出了 《Gmeek博客本地化管理方案:桌面应用与命令行工具设计与对比》 | GitHub 链接。现在回头看,这一步很重要。因为一旦你一开始就说“给我做个 Gmeek 的本地工具”,后面很容易一路滑到功能堆砌里去。相反,先把痛点写清楚,后面很多判断都会轻一些。
ima 在这里做的不是直接给答案,而是帮我把零散的不满整理成了一份能继续讨论的文档。最后沉淀下来的就是 docs/gmeek-need-doc.md。里面先把现有工作流的痛点拆开,再去比较桌面应用和命令行工具两条路线。等这份文档出来以后,事情才算真正从“我觉得不方便”变成了“我知道我到底想解决什么”。
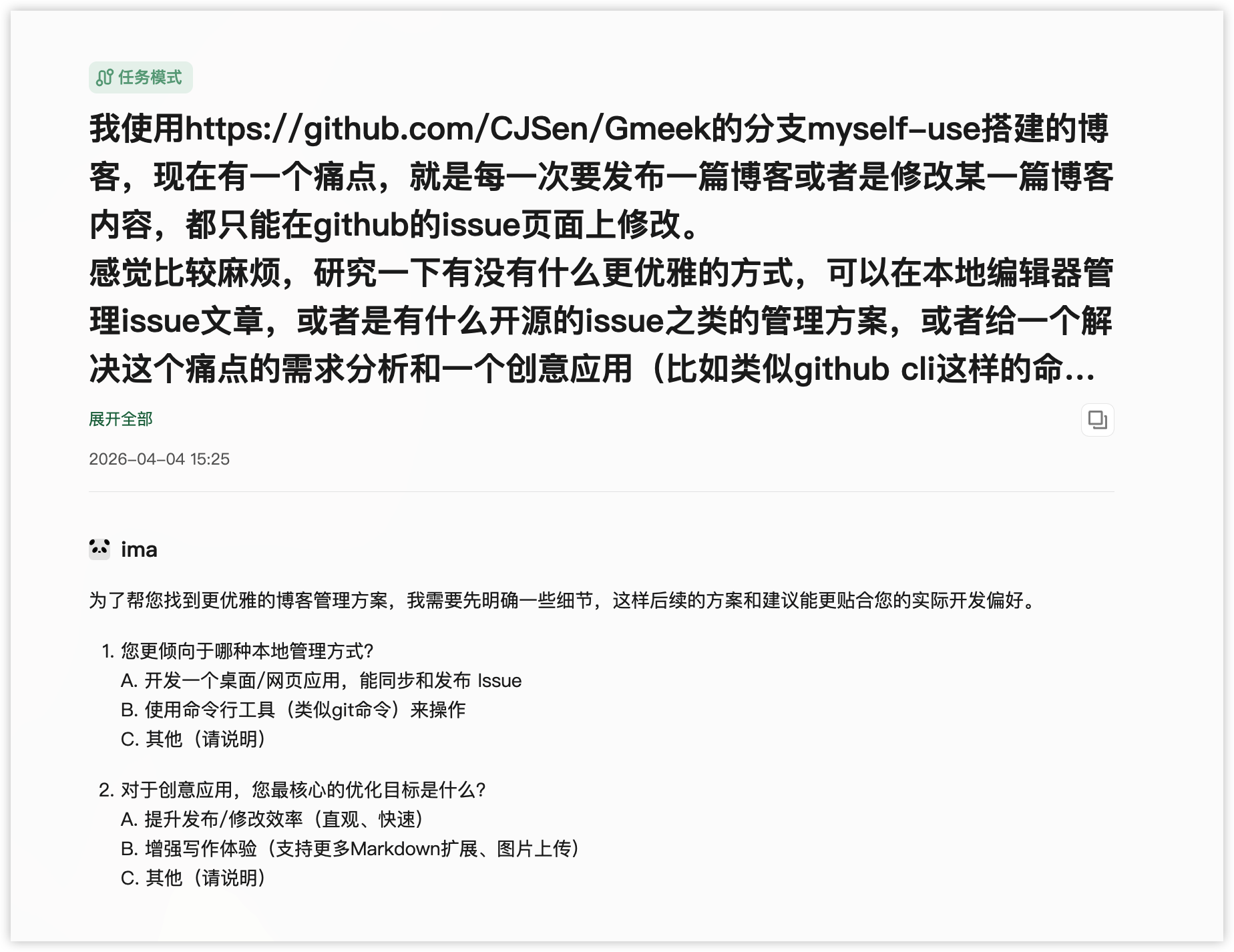
ima调研过程(点击可查看大图)
上面这张图对我来说挺有代表性的。它不是在“生成一个答案”,而是在帮我把问题慢慢收束成一份后面还能继续使用的材料。
真正的分水岭,是把模糊想法交给流程收敛
有了 《Gmeek博客本地化管理方案:桌面应用与命令行工具设计与对比》 | GitHub 链接 以后,我没有立刻开始写代码,而是把这份文档交给了 superpowers(一个 skill) 里的 brainstorming。这一步对我来说是整个过程里真正的分水岭。
原因很简单。调研文档解决的是“问题在哪里”,但还没有解决“第一版到底做什么”。如果这时候直接进入 coding,最后大概率会做成一个什么都想带一点、但每一块都不够实用的东西。brainstorming 的价值不在于它问得多聪明,而在于它强迫我先把边界说清楚:目标是什么,约束是什么,第一版明确不做什么。
在这个阶段,其实花了挺多时间。因为一开始它真的只是一个想法,并没有清楚到“第一版到底要做什么”。调研给了桌面端和终端两种方案,在头脑风暴过程中,和 AI 来回讨论,最终才把方向定下来。
中间还有一个比较关键的分歧:到底做不做“管理”。我曾经想过,既然 Gmeek 产物里会自动生成一个 backup 文件夹,里面保存了所有已发布文章的 .md 文件,那是不是可以强绑定仓库,依托 Git 顺手做版本管理。但最后脑暴下来,还是把路线收住了:做一个适配 Gmeek、但本质上更通用的 issue 管理工具,不做额外的版本管理,简单最好。
后来落出来的 spec 很能说明这个阶段的作用。比如第一版不做 publish 独立命令、不做 diff、不做冲突合并、不做增量同步、不做图片上传,也不做桌面应用。你会发现,这些“不做”比“要做什么”更重要。因为一旦这些边界被写下来,后面的实现就不会一直被新想法拖着走。(superpowers 相关产出)
我也越来越明显地感觉到,所谓 vibe coding,如果没有前面的收敛流程,其实很容易把“表达得像需求”误当成“已经想清楚需求”。superpowers 在这里更像一个会不断追问的流程框架,而不是一个直接产出结果的捷径。
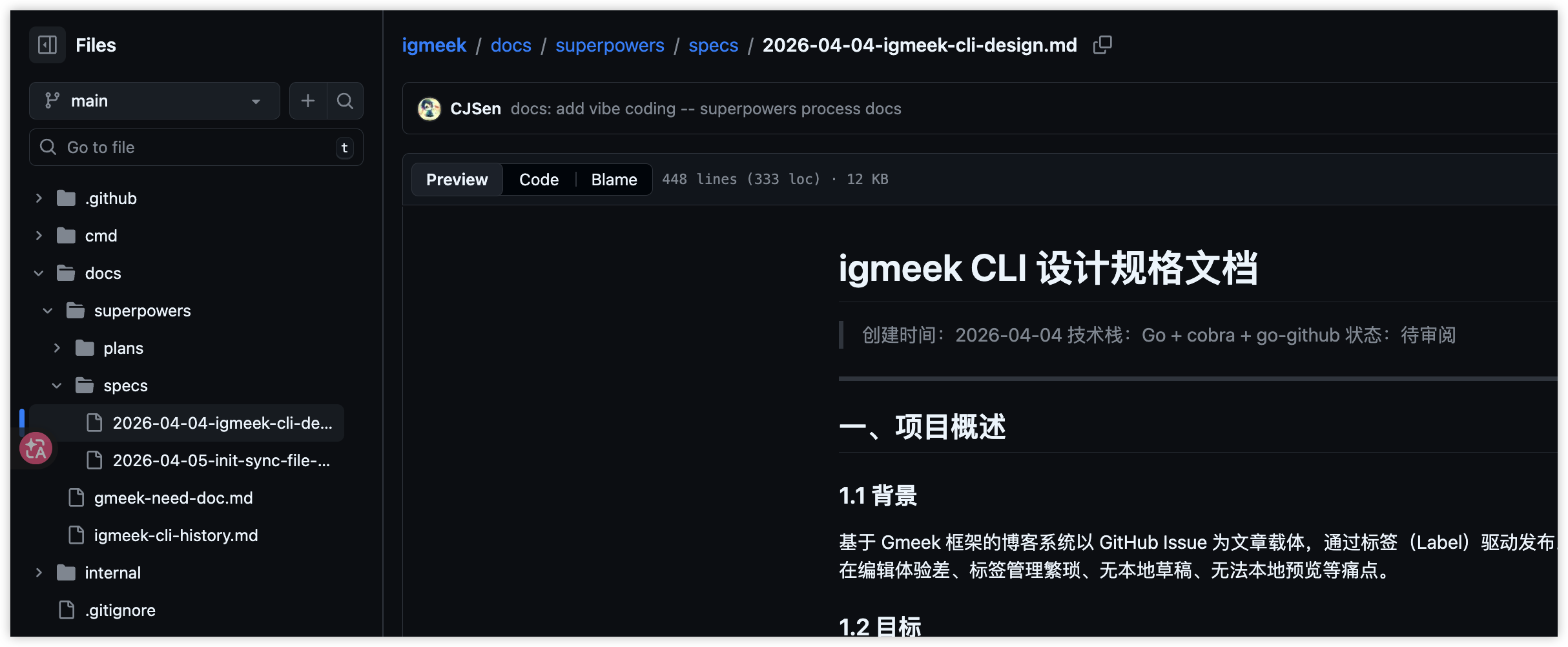
设计收敛阶段的文档产物(点击可查看大图)
这类设计文档的价值,不是看起来专业,而是它真的帮我把边界写死了:哪些是第一版必须有的,哪些则明确先不做。
路线确定以后,coding 反而变成最顺的那一段
路线收住以后,后面的节奏反而顺了。先有 spec,再进入 writing-plans,把实现拆成一组很具体的任务,然后再开始 coding。这个顺序看上去有点啰嗦,但它的好处是你不会在写到一半的时候反复想“我现在到底是在补功能,还是在重写设计”。
坏处当然也很明显:太费 token 了,而且触发概率还高,以至于我很多时候都会忍不住强调一句“不要使用 skill”。
从现有文档里也能看出来,这个项目不是一句提示词直接长出来的。docs/superpowers/plans/2026-04-04-igmeek-cli-implementation.md 把它拆成了一组非常细的任务:从 Go 模块初始化、配置目录、token 解析,到 GitHub API 封装、索引管理、Markdown 读取,再到 sync、new、update、del、label、repo 这些命令,一步步往前推。
我后来很喜欢 docs/igmeek-cli-history.md 这种文件,因为它反映了一件很现实的事:当开发不是在一个连续对话里完成,而是被拆成多个 session 时,你就得有一份能恢复上下文的材料。历史文件里甚至直接写了“14/14 个 Task 全部完成”,以及下一次新 session 应该从哪里接上。这种东西看起来不酷,但真的很有用。
如果只看表面,可能会觉得 coding 才是 vibe coding 最神奇的部分。可对我这次来说恰恰相反。真正顺的,是在设计和计划已经比较清楚之后,把那些确定的东西一个个落下去。那时候 opencode 的优势才比较明显:它能持续接住上下文,按结构往前推,而不是每次都从头解释一遍项目是什么。
哈哈,依稀记得上学的时候,我最讨厌的一门课就是《软件工程》。要产生一个软件,前期准备时间太多;而且我本来也不喜欢写文档。到了 AI 时代,这些事确实都变得容易了很多。
Tips:vibe coding 很容易遇到上下文爆掉的问题。虽然 TUI IDE 通常会自动处理,但我还是建议经常让它总结当前对话、生成 history 文件,然后新开一个对话载入文件继续处理。另外,不同任务尽量拆到不同对话里做,会更稳一些。
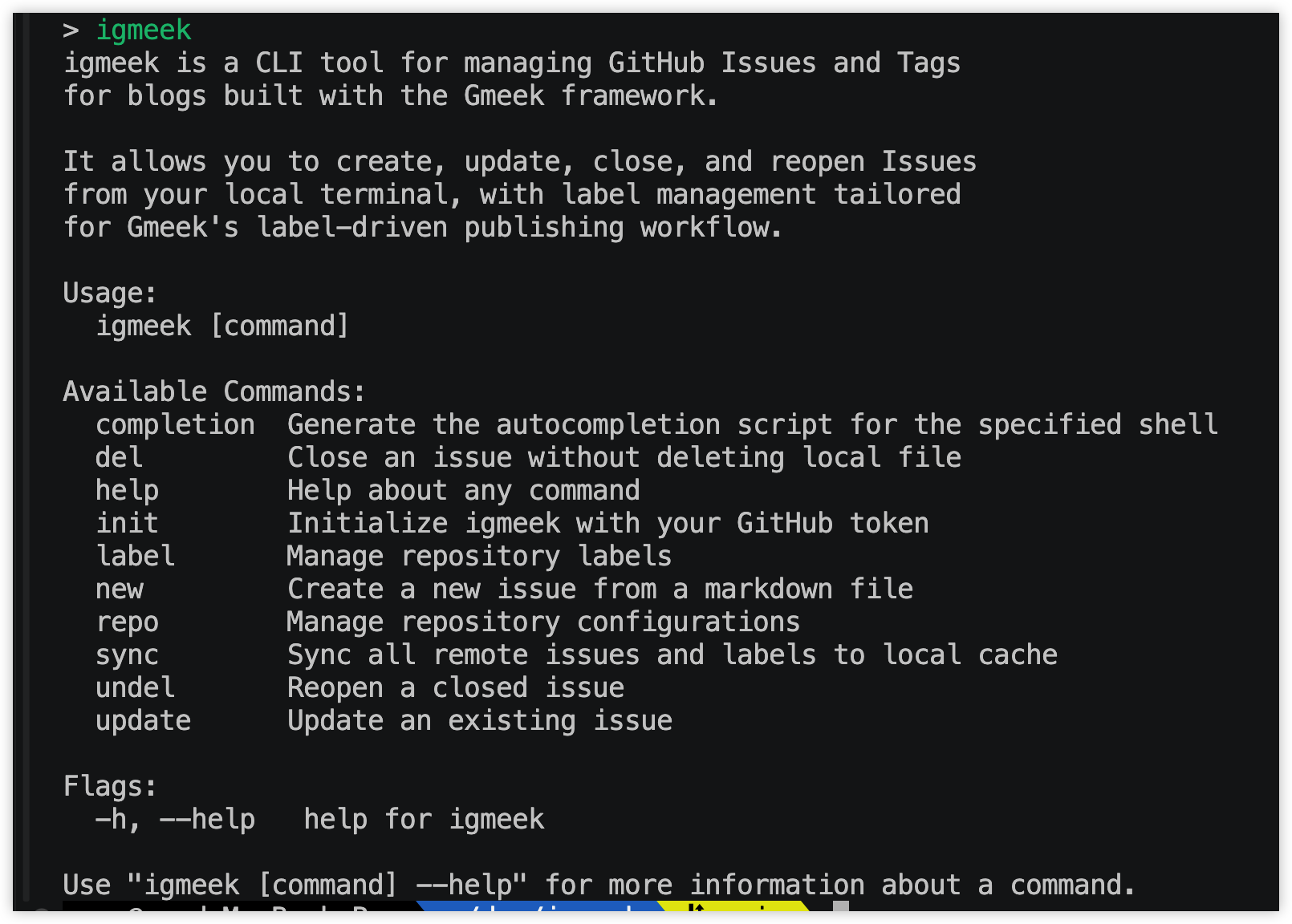
第一版 CLI 已经成型(点击可查看大图)
从这里开始,项目才真正有了“工具”的样子,而不只是一个能跑的实验品。
真正磨人的,不是从 0 到 1,而是从“能跑”到“能用”
如果到这里就收笔,那这篇文章就很容易变成“看,第一版很快就出来了”。但真实情况不是这样。
第一版出来以后,项目真正开始变得像一个工具,而不是一个原型。也正是在这个阶段,我最明显地感受到:vibe coding 最容易让人误判的,就是进度。很多时候你会觉得“主体功能都齐了”,可只要一进入真实使用场景,就会发现还有一堆小地方在拖后腿。
最典型的一轮,就是后面那次围绕 init 和 file 路径匹配的微调。在测试中,我的要求其实说得很直接:init 不应该只填 token,还应该顺手填一个初始 repo、跑一次 sync,最后把结果和数据路径都告诉你;另外,输入 file 路径的时候,不能只按绝对路径或相对路径硬比,否则根本匹配不上对应的 issue。
这两个问题都不算“炫技型问题”,但都非常像真实使用时会最先撞到的那类问题。后面你会看到,针对这次调整,项目又重新走了一遍收敛流程,补了新的 design 和 implementation plan。也就是说,哪怕是看起来很小的一次修补,最后也不是“顺手改一下”就完事,而是重新把问题定义、影响范围、错误处理和测试策略理了一遍。
这部分让我印象很深。因为它提醒我,工具真的开始可用,靠的往往不是主功能,而是这些工程化的小地方有没有被认真对待。init 里多一步 repo 和 sync,路径匹配里多一层 basename fallback、歧义提示和相似文件建议,帮助信息和 README 里的 token 权限说明,单独看都不大,但少一个都很容易让第一次上手的人卡住。
说得再直白一点,从“能跑”到“能用”的这段路,恰恰是 vibe coding 最不能偷懒的地方。因为这里没有那种很大的成就感,只有一连串细小但必要的修整。你不盯,它们就会一直留在那里。
最后一公里,是测试把想象打回现实
再往后,项目进入了我很喜欢、也很容易被忽略的一段:测试。不是那种“跑一下单测,看到绿就收工”的测试,而是开始认真写手工测试清单、反馈模板,甚至专门为 worktree 分支准备测试材料。
其实测试也是我一直很头痛的问题。不过到了 AI 时代,这件事也被大幅简化了,有时候真的只需要几句话,就能先把一份像样的检查清单搭出来。
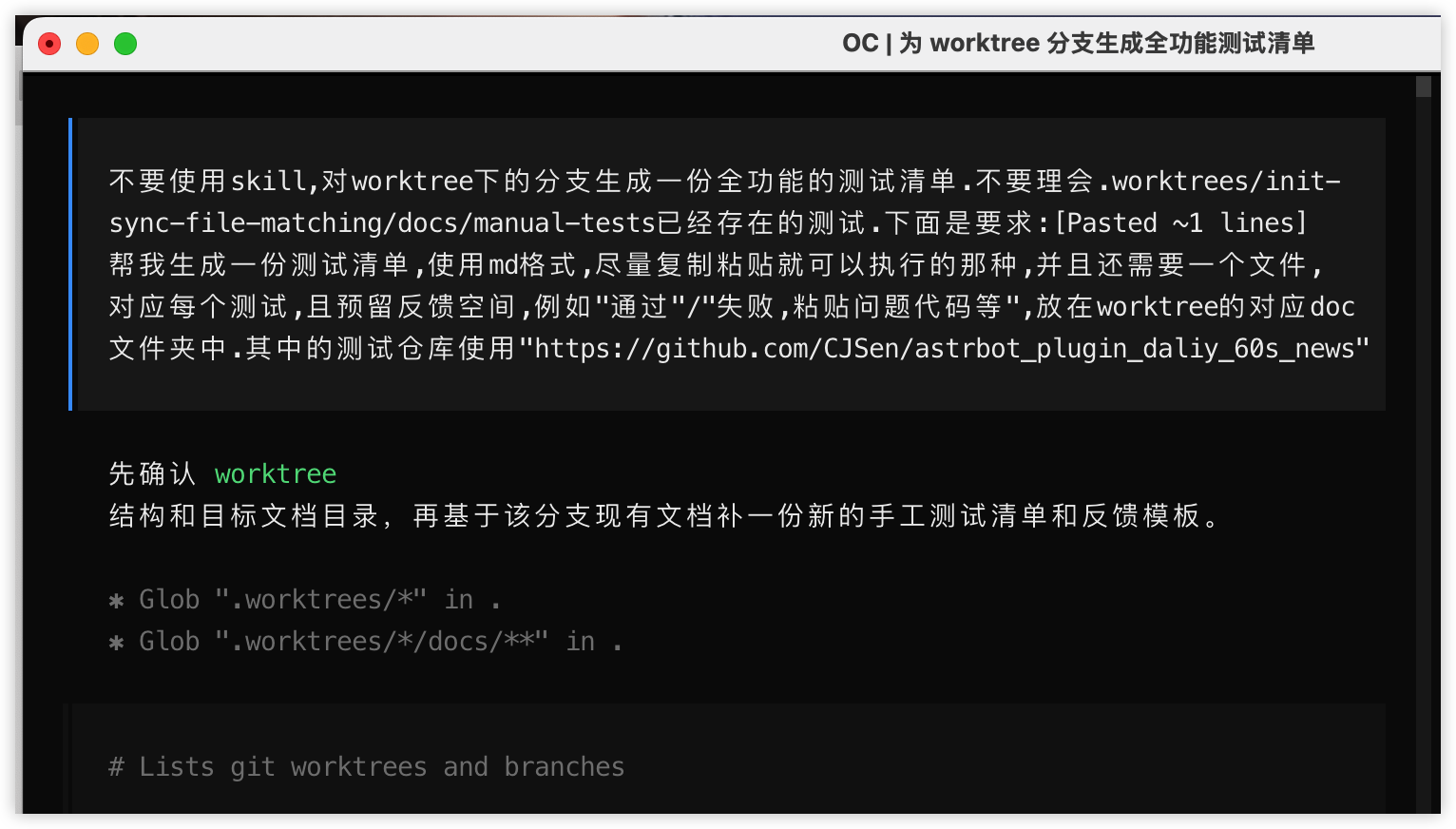
手工测试清单(点击可查看大图)
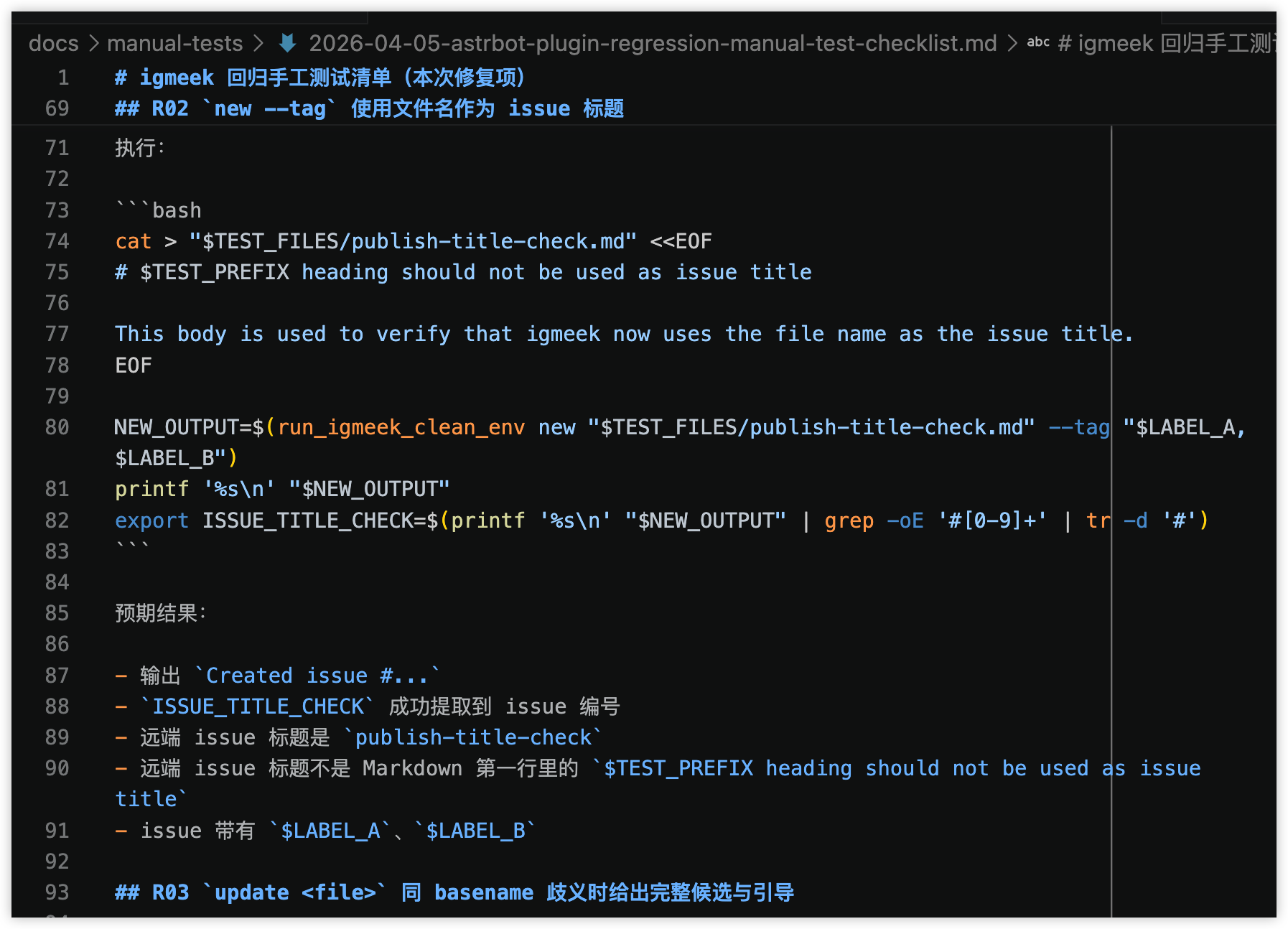
测试素材与结果记录(点击可查看大图)
docs/manual-tests/2026-04-05-manual-test-checklist.md 和 docs/manual-tests/2026-04-05-manual-test-feedback.md 很能说明问题,不过这两个文件本身还有些瑕疵,我就没有把它们放进仓库里。前者不是一句“请手动测试一下”,而是从测试前准备、临时配置目录、测试仓库,到每条命令怎么跑、预期输出是什么,都写得很细;后者则给每个测试项都留了结果和反馈位置。这说明项目已经不是在验证“功能大概对不对”,而是在验证“别人能不能照着跑起来,哪里会卡住,失败时该留下什么信息”。
这时候你就会发现,测试其实不是收尾动作,而是重新认识项目的一轮过程。因为每多写一个 checklist,你就会重新审视一次接口、路径、输出文案和失败语义。很多前面看上去已经确定的设计,到了这一步又会暴露新的缺口。
所以我后来越来越不愿意轻易说“第一版完成了”。更准确一点的说法应该是:第一版到这里已经长成一个可以被认真验证的东西了。它当然比一开始更完整,但也正因为开始认真测试,很多原本没暴露的问题才会更早出来。
为什么说这是一次“不完全体验”
最后回头看,这条链路其实很清楚:前期调研我主要用了 ima;调研文档出来以后,再借助 superpowers 里的 brainstorming 和后续的规划流程,把路线收敛下来;路线定了以后,真正进入 coding 阶段,主要依赖 opencode 一点点把结构、命令和文档搭起来;而在第一版出来以后,真正把它往可用状态推近的,反倒是后面的微调和测试。
这也是我为什么想把标题写成《一次 vibe-coding 的不完全体验》。这里的“不完全”,不是客套话,也不是故意留白,而是因为这次体验本身就不是一场完美演示。它更像一次真实开发:有调研,有收敛,有推进,有返工,也有测试把想象打回现实的时候。
如果非要总结一句,那就是:vibe coding 最舒服的地方,是当方向已经比较清楚时,它能让推进变得更快;最不能省的地方,则还是那些老问题,需求判断、边界控制、错误处理、验证和修整。工具可以帮你提速,但不能代替你决定项目该长成什么样。
而对我来说,这恰好也是这次体验最有意思的部分。它没有让我相信“以后开发都交给 AI 就行”,反而让我更确定了一件事:真正重要的不是谁在敲代码,而是谁在持续判断这段代码到底该不该这样存在。
至于后续
第一版已经发布,涵盖了基本的 issue 发布流程。如果你也在使用 Gmeek 搭建博客,欢迎试试我的这款软件:igmeek,麻烦动动你的小手点点star。该工具目前提供 Windows / Linux / macOS 版本。
但是需要注意的是,第一版目前只支持不带图片的 Markdown 文件。这是为什么呢?因为我还没完全想好图片这块该怎么做,GitHub 的issue接口本身也没法直接上传图片。所以我现在在考虑,是不是要配图床,或者干脆在 README 里介绍一种“单开一个仓库,把 GitHub 当图床”的方式。不过目前思路还比较乱,后面再慢慢脑暴吧。
希望自己可以早点把第二版内容更新上。
不过说到 README,我还是要高喊一句:AI 写 README 真的太爽了啊!
致谢
感谢Gmeek的所有开发者,有这么好用简单的一个博客
感谢Linux.do站的@冰 佬提供的公益站,本次vibe coding 基本全程使用。
感谢opencode,本次vibe coding全程基于opencode,和其提供的免费模型,在冰佬公益站崩了的时候顶了上去。